2018 AI Frontiers Keynote
The ABCDs of AI-Native Startups
In late 2018, I gave a talk on how I looked at investing in the coming wave of AI application startups. Sharing a couple of the slides publicly rather than sending it to founders one-off, and including some of the original voiceover notes, even though it deserves an update based on the massive breakthroughs in general models and transfer learning! Still, we're barely in "inning two" from an application perspective.

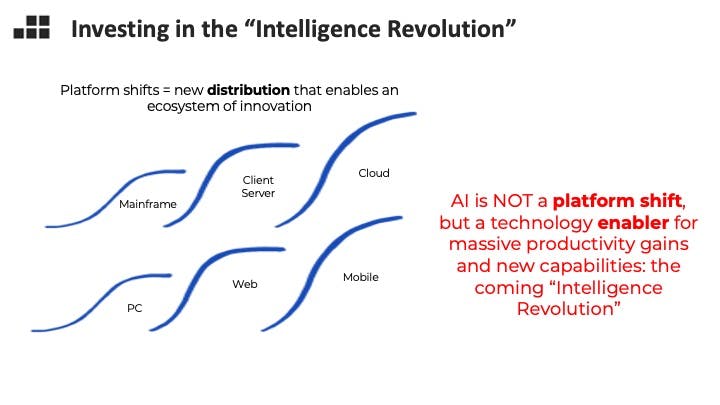
Many great venture backed companies over the past 15 years have simply been the reinvention of existing categories of software in the cloud. Cloud is a delivery method that enables agility, consumption based pricing, and reduced burden on the customer. The lift and shift has remade and expanded categories such as ERP and CRM. Others have leveraged capabilities and distribution of mobile. Uber reaches consumers and drivers through a mobile app, and it needs real time location data off your smart phone to operate. As the last platform shifts mature, we’re starting to think about what could be the next supercycle, and I think it’s AI.
I am paying attention to it as a broad enabler and a change in the way software products get built, from decomposition and engineers writing code, to iterative optimizations, with engineers feeding a model curated data. AI is NOT a platform shift, because I define that as a new distribution paradigm that enables an ecosystem of innovation, such as the web. AI is instead an a technical enabler for massive productivity gains and new product capabilities: the coming “Intelligence Revolution.”
There’s a massive rift between the haves and have-nots in AI today. The majority of you in attendance at this conference are engineers and researchers that work for organizations like Google, Facebook, Amazon, Tesla, Microsoft, Nvidia. These are companies whose businesses have been transformed by AI. Your average F500 company does not yet have the capabilities to build software 2.0 in house – we are in the first inning, but over the coming two decades, I believe it will transform their businesses anyway.

AI at Google started with ads prediction, and that is permeating into every nook and cranny. Even tier-2 ML-driven organizations such as Uber have at most a few models that matter today. Most enterprises will adopt more piecemeal, because it’s hard to formulate a clearly measurable business-wide objective function such as “sell more ads,” or "price this ride." It’s a monumental task that requires expertise and organizational will to remake their organizations, hire the requisite talent, collect the data they need. Your average company will start with all the nooks and crannies, and the ecosystem and talent base will improve as tooling gets better and the talent base grows. The largest internet companies are building entire ML research and deployment infrastructure tooling teams, and those innovations will eventually be packaged for others to benefit from. Frameworks and models are being open sourced. AI is an increasingly popular concentration in Computer Science departments as students become enamored of the unreasonable effectiveness of deep learning techniques, more data, and the next algorithmic innovation on the horizon. Perhaps most importantly, enterprises will outsource non-core problems to software vendors and partners, which is a huge opportunity for startups.

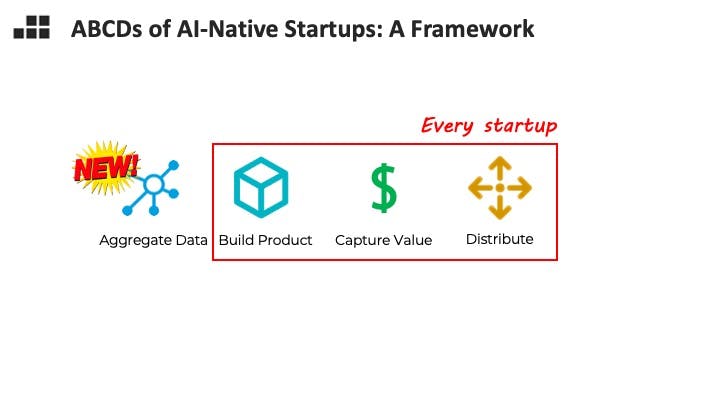
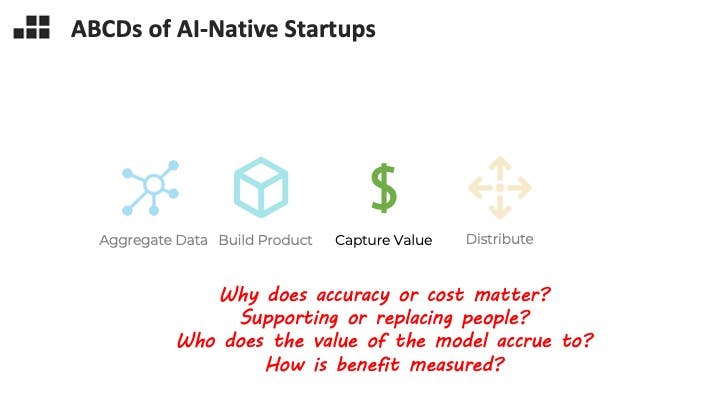
Which brings us to our major topic today: building AI native startups. I’m going to walk you through a quick framework, the ABCDs, of how I think about AI native company-building. Every startup, going from zero to one, basically needs to build product, capture value from customers, and distribute the product to customers. AI adds a new complication – how are you going to train your model?
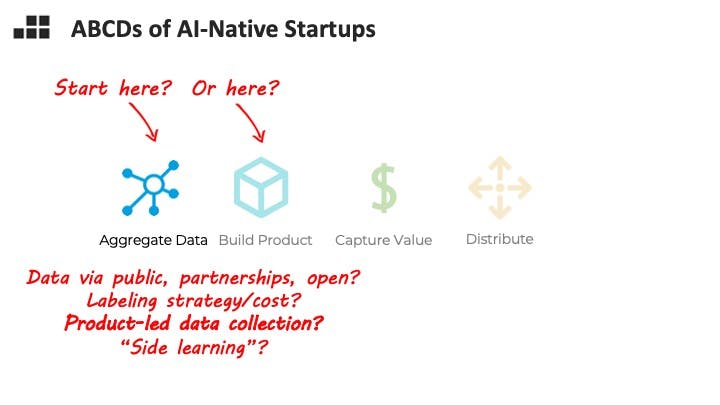
Many AI companies face a chicken-or-egg dilemma. They need a dataset to build a sufficiently good model and embed it into their product – and often the most clever way to get the data you need is to collect it within your product. One thing I’m looking for is a strategy to get past this bootstrap issue in a capital efficient way.
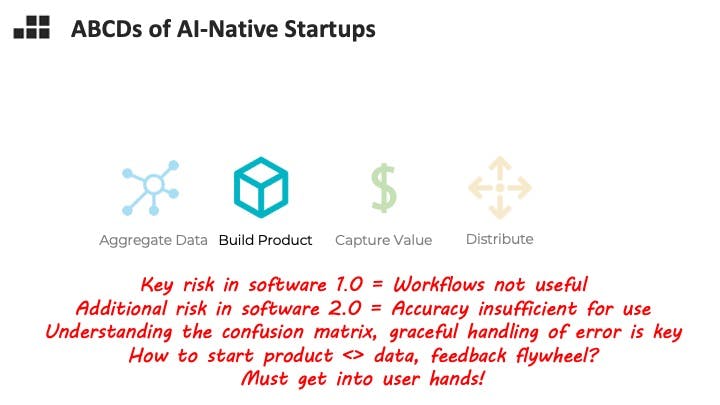
An interesting conundrum for AI entrepreneurs and investors is that there is a new flavor of risk – what if they can’t get model performance to be sufficiently good? What does sufficiently good mean? Different use cases have different sensitivities. How can you know if you can make it over that hump before you’ve trained on the data? I am looking for founders that combine experience or intuition for this problem with the product sense to gracefully handle errors.
AI is not a panacea for software. While we can imagine the thousands of use cases for it, some are worth more than others, easier to distribute than others, face less strangulating regulation. For example, work into intelligent radiology dates back to at least 1959 ("We look to invent an electronic scanner computer to look at chest photofluorograms, to separate the clearly normal chest films from the abnormal chest films,” said Lee B. Lusted, MD, the founder of the Society for Medical Decision Making) but a combination of challenging value capture in a fee-for-service healthcare system, technology bought in hardware systems and user resistance means that despite accuracy that is superior to human experts, AI-supported radiology is still not broadly adopted.
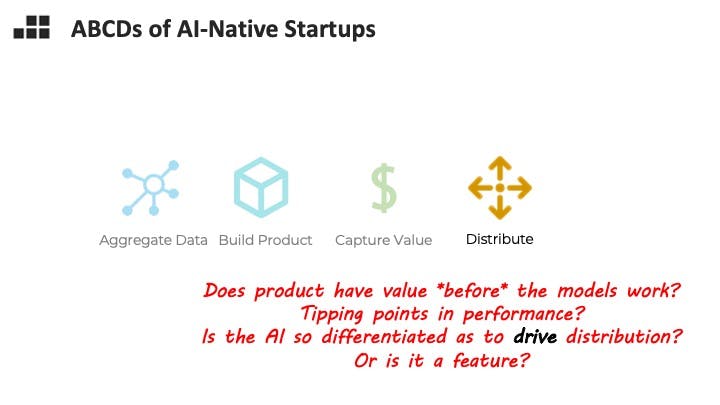
Many paths to startup distribution for AI-native companies will have nothing to do with the AI. It's a problem to be tackled separately - with product-led distribution, clever marketing or partnerships.
One core case study for the talk was 头条 Toutiao (sister and predecessor product to Tiktok within Bytedance). Bytedance has long been committed to being an "AI-first company" and was particularly clever about the chicken-and-egg of initial data collection and a product that was good enough to self-distribute.

Some case study slides excluded, but that's the core of the talk. Have feedback or questions? Should I cover: very large models, a 2022 update of this framework with stories of failure/success, or deep dive into AI application areas for my next talk?
Discuss: s at sarahguo.com
