
Self-Serve Apps for ML Teams
Our Investment in Baseten
Written with Jason Risch
When Tuhin Srivastava walked into the Greylock offices at 8:00 am in late 2019, he was only a few months into unemployment post-acquisition of his startup.
He declared, without any preamble, “I’m thinking about starting a new company in ML. We just really need to take the whole pipeline cost down, and improve the iteration cycle. Otherwise, most teams are never going to ship.”
I had known Tuhin for several years, having met him and Phil Howes early in his prior startup journey and loving their talent, entrepreneurialism, user centricity and product sense. Ever since, I’d been looking for an opportunity to work with them. As it turned out, this was the moment I had been waiting for.
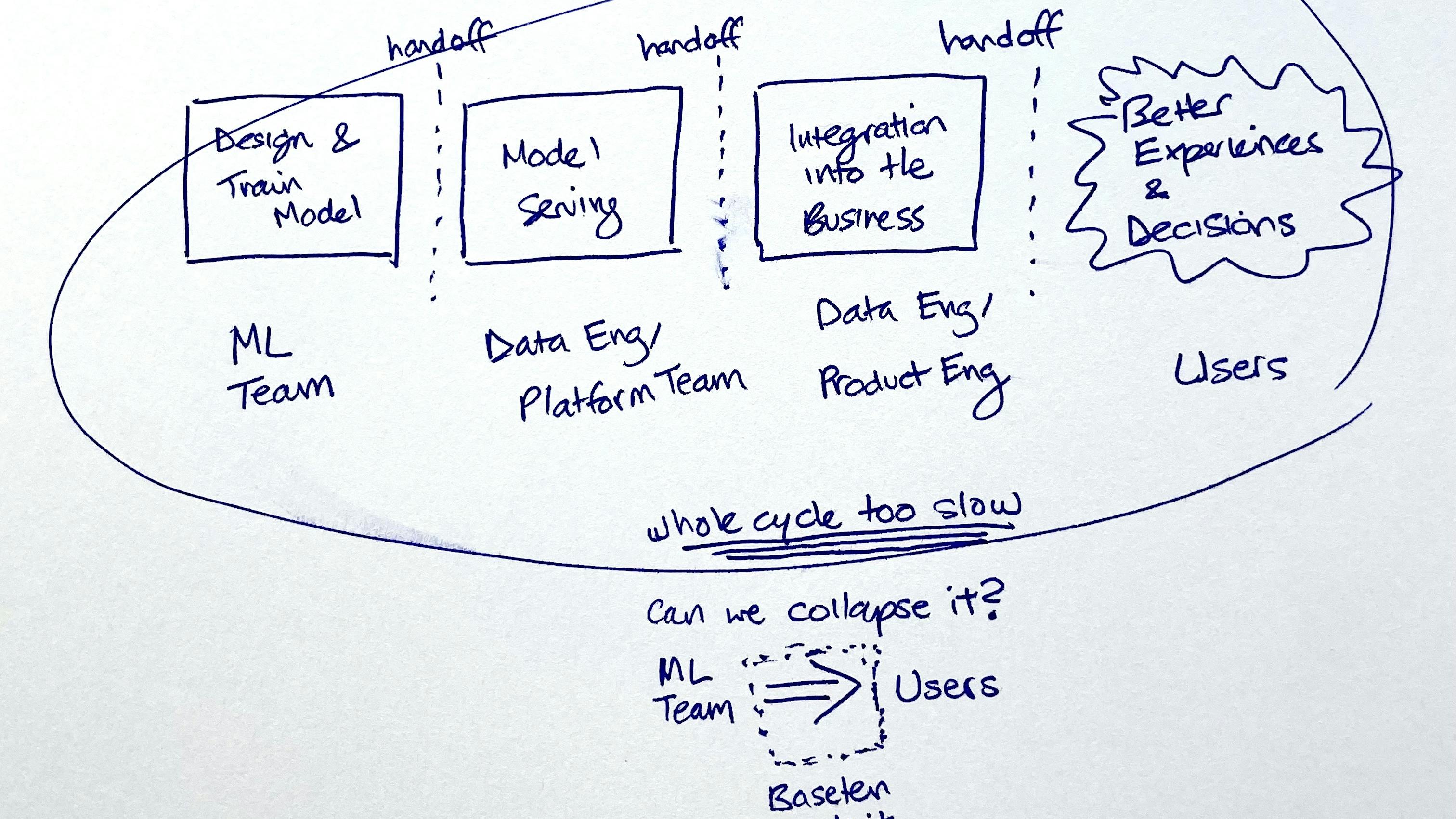
We proceeded to talk for several hours about the idea that became Baseten. I found the diagram from my first meeting notes, which I’ve now seen Tuhin recreate some form of many times over the past two years.
THE CHALLENGE OF UNLOCKING ML’S VALUE
We are at an extraordinary point of time in the arc of machine learning. Increased sophistication in collecting and managing data, advancements in model architectures (giant transformers!), open-source pre-trained model availability, and ever larger and cheaper compute all seem to come together to promise tremendous value for enterprises – and potentially even an economy of abundance. McKinsey famously estimated that industries could unlock $5T+ of value from integrating ML. And yet, real progress has fallen short.
We constantly hear from technical and business leaders that despite significant investments in AI, they are nowhere near reaching that promised land. They describe a fatigue that has begun to set in, believing AI to be the domain of a few elite companies. We hear the frustrations from individual contributors that their models become shelfware.
MOVING FROM RESEARCH TO IMPACT
Baseten’s co-founders Tuhin Srivastava (CEO), Amir Haghighat (CTO) and Philip Howes (Chief Scientist) started the company based on their collective, first hand experience. At pioneering creator marketplace Gumroad, Tuhin and Phil were data scientists who had scrappily become full-stack engineers so they could use ML to defend against fraud and abuse, and moderate user-generated content. At Clover Health, Amir had led teams that developed ML models to drive population health management.
In talking to their friends at companies of differing scales and verticals, they realized the pain they faced was widespread.
Operationalizing ML requires high coordination, highly skilled engineering and product work beyond data science. Today, once they have trained a model, data science teams need to coordinate with data teams to implement data pre and post-processing. They need to work with devops and backend engineers to deploy and serve the model as an API (with the output usually being a prediction, classification, or generation of some content). From here, companies need to integrate that API into existing systems and processes, or invest front-end development and design resources to build new interfaces for end users, as well equip the end users with sufficient context to interpret and accept or reject the ML predictions. They need to stitch all of this together, scale it and monitor it.
This is a gargantuan task, and today only the most motivated and well-resourced teams succeed. Even then, they only manage to ship their highest-priority use cases.
Under the status quo, even “simple” models can take 6+ months to ship. Many projects run behind schedule as stakeholders struggle to align and investments are withdrawn or resources reallocated. When teams persevere to deliver to the end user, they often realize there was an understanding gap between the supposed spec, and what business users actually needed. Often, after all this engineering effort, teams find out they need to collect more data or change their labeling. Without iteratively incorporating feedback, context around the data, and domain knowledge from business users, the model builders risk constructing models that perform sub-optimally and do not become integrated into business decision-making.
In response, the Baseten founders envisioned a unified platform for data science teams to build full-stack custom ML applications in hours instead of months. We signed up for that vision, co-led their seed with South Park Commons and dove in. The team built and iterated towards a v1, having hundreds of conversations with end users and buyers along the way. They also recruited an exceptional early team, hailing from GitHub, Google, Uber, Amazon, Palantir, Atlassian, Confluent, Yelp, AirTable, and more.
SOFTWARE FOR SHIPPING (ML-ENABLED) SOFTWARE
Baseten isn’t “no-code,” it’s efficient code. It is a powerful software toolkit that empowers technical data science teams to serve, integrate, design, and ship their custom ML models efficiently. They can write arbitrary code wherever they need to, and not where they don’t. It speaks their language (python) and tools (jupyter notebooks), and it unblocks ML efforts that today are bottlenecked on infrastructure, backend and frontend engineering and design resources. It collapses the innovation cycle for ML apps, making cheaper experimentation and therefore more success possible. Under the hood, it’s powered by a scalable serverless platform, and designed for public or private cloud deployment. Baseten is modular, and we’re excited to already be receiving strong community interest in contributing to an ecosystem of models, components and integrations that allows for greater leverage for every ML team.
- With Baseten, users can:
Create interactive model evaluation apps, demos, prototypes — build web apps to show off the power of machine learning models and get feedback from stakeholders and users to close the feedback loop sooner, or extend the visibility of new research - Build tools for machine learning — create custom tools that help you train more models and make your existing models better (e.g. model output and data browsers, labeling interfaces, model monitoring workflows)
- Build production-grade, stateful, workflow-integrated ML apps — e.g. integrate fraud models into complex financial decisioning, or use a classifier like toxic-bert from the Baseten “model zoo” to power a content moderation queue
INVESTING IN BASETEN
Jason Risch and I are thrilled to be leading the Series A investment for Greylock, and I am joining the board.
Working closely together with the team, we saw strong demand for the product from both commercial teams and the research community, and success with early adopters such as Pipe, Patreon and Primer. Our conviction as investors only deepened. We are excited to team up with an exceptional set of coinvestors across AI, developer platforms, design and community, including Lachy Groom, Ray Tonsing (Caffeinated Capital), Andrew Ng (AI Fund), and angels including Greg Brockman, Dylan Field, Mustafa Suleyman, DJ Patil, Dev Ittycheria, Jay Simons, Jean-Denis Greze, and Cristina Cordova.
I recently sat down with Tuhin on the Greymatter podcast. You can listen to our conversation at the link below, on YouTube, or wherever you get your podcasts. And read more from Tuhin and the team here.
Sign up for the free open beta – or if you want to build software that helps more ML make it into the real world, we’re hiring!